LC Ladder Filter Synthesis via Backpropagation¤
This notebook shows how automatic differentiation can synthesise a 3rd-order Butterworth lowpass filter from scratch, recovering the analytically correct component values purely through gradient descent.
The traditional approach¤
Conventional filter design looks up pre-computed prototype tables (Butterworth, Chebyshev, elliptic …), scales the normalised g-values to the desired impedance and cutoff frequency, then verifies the result in a simulator. The design and the simulation are separate steps.
The circulax approach¤
Because circulax is built on JAX, the forward pass — evaluate the S-parameters of a circuit — is fully differentiable. That means we can:
- Define a target response (e.g. an ideal Butterworth magnitude).
- Write a loss function that measures how far the current response is from the target.
- Call
jax.gradto get exact gradients of the loss with respect to component values. - Use an off-the-shelf gradient-descent optimiser (Adam) to drive the parameters to the optimum.
The circuit never needs to be re-compiled: compile_circuit runs once, and from that point the optimiser is just iterating over a smooth JAX function.
Circuit: 3rd-order T-section LC lowpass¤
50 Ω source and load resistors provide the reference impedance. The Butterworth prototype g-values for N = 3, Z₀ = 50 Ω, f_c = 100 MHz are:
| Element | Formula | Value |
|---|---|---|
| L1 | g₁ · Z₀ / (2π f_c) | 79.58 nH |
| C1 | g₂ / (2π f_c · Z₀) | 63.66 pF |
| L2 | g₃ · Z₀ / (2π f_c) | 79.58 nH |
We start the optimiser from deliberately wrong values — roughly 3× off — and watch gradient descent converge to the Butterworth solution.
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
import numpy as np
import optax
from circulax import compile_circuit
from circulax.components.electronic import Capacitor, Inductor, Resistor
# Enable 64-bit precision throughout — important for accurate S-parameter
# gradients, especially at high frequencies where small perturbations matter.
jax.config.update("jax_enable_x64", True)
plt.rcParams.update({
"figure.figsize": (8, 3.5),
"axes.grid": True,
"lines.color": "grey",
"patch.edgecolor": "grey",
"text.color": "grey",
"axes.facecolor": "white",
"axes.edgecolor": "grey",
"axes.labelcolor": "grey",
"xtick.color": "grey",
"ytick.color": "grey",
"grid.color": "grey",
"figure.facecolor": "white",
"figure.edgecolor": "white",
"savefig.facecolor": "white",
"savefig.edgecolor": "white",
})
1. Butterworth analytical targets¤
For a 3rd-order Butterworth prototype with normalised g-values [g₁, g₂, g₃] = [1, 2, 1], the T-section element values scale as:
The ideal transmission coefficient magnitude follows:
which is maximally flat at DC and has a −3 dB point exactly at f_c.
# ── Butterworth prototype parameters ──────────────────────────────────────────
Z0 = 50.0 # reference impedance (Ω)
f_c = 1e8 # cutoff frequency (Hz) = 100 MHz
wc = 2 * np.pi * f_c
# N=3 Butterworth g-values: [1, 2, 1]
g1, g2, g3 = 1.0, 2.0, 1.0
L_target = g1 * Z0 / wc # L1 = L2 (symmetrical T-section)
C_target = g2 / (wc * Z0) # C1 (shunt)
print(f"Butterworth targets (N=3, Z0={Z0:.0f} Ω, fc={f_c/1e6:.0f} MHz):")
print(f" L1 = L2 = {L_target*1e9:.4f} nH")
print(f" C1 = {C_target*1e12:.4f} pF")
# ── Starting values — 3× off from the Butterworth solution ───────────────────
L1_init = 25e-9 # nH (target: ~79.6 nH)
C1_init = 200e-12 # pF (target: ~63.7 pF)
L2_init = 25e-9 # nH (target: ~79.6 nH)
print("\nStarting values:")
print(f" L1 = {L1_init*1e9:.1f} nH ({L1_init/L_target:.1f}× target)")
print(f" C1 = {C1_init*1e12:.1f} pF ({C1_init/C_target:.1f}× target)")
print(f" L2 = {L2_init*1e9:.1f} nH ({L2_init/L_target:.1f}× target)")
Butterworth targets (N=3, Z0=50 Ω, fc=100 MHz):
L1 = L2 = 79.5775 nH
C1 = 63.6620 pF
Starting values:
L1 = 25.0 nH (0.3× target)
C1 = 200.0 pF (3.1× target)
L2 = 25.0 nH (0.3× target)
# ── Netlist: 3rd-order T-section LC lowpass ───────────────────────────────────
#
# Rp1,p1 ── L1 ── junction ── L2 ── Rp2,p1
# (Port1) │ (Port2)
# C1
# │
# GND
#
# Port nodes are defined by 1 TΩ probe resistors — negligible effect on the
# circuit but they register the named AC ports. The Z0=50 Ω source and load
# terminations are injected by circuit.ac(...), NOT as explicit resistors.
# Including explicit source/load resistors AND letting AC add Z0 would give
# 25 Ω effective termination and the wrong Butterworth values.
net_dict = {
"instances": {
"GND": {"component": "ground"},
"Rp1": {"component": "resistor", "settings": {"R": 1e15}}, # 1 TΩ probe — Port 1
"L1": {"component": "inductor", "settings": {"L": L1_init}},
"C1": {"component": "capacitor", "settings": {"C": C1_init}},
"L2": {"component": "inductor", "settings": {"L": L2_init}},
"Rp2": {"component": "resistor", "settings": {"R": 1e15}}, # 1 TΩ probe — Port 2
},
"connections": {
"GND,p1": ("Rp1,p2", "C1,p2", "Rp2,p2"),
"Rp1,p1": "L1,p1",
"L1,p2": ("C1,p1", "L2,p1"),
"L2,p2": "Rp2,p1",
},
"ports": {"in": "Rp1,p1", "out": "Rp2,p1"},
}
models = {
"ground": lambda: 0,
"resistor": Resistor,
"inductor": Inductor,
"capacitor": Capacitor,
}
circuit = compile_circuit(net_dict, models)
y_dc = circuit.dc()
print(f"System size: {circuit.sys_size} unknowns")
print(f"Named AC ports: {list(net_dict['ports'])}")
print(f"\nComponent groups: {list(circuit.groups.keys())}")
System size: 6 unknowns
Named AC ports: ['in', 'out']
Component groups: ['capacitor', 'inductor', 'resistor']
2. Optimisation strategy¤
Why log-space?¤
Inductance and capacitance values span many decades (nH to µH, pF to nF). Optimising in log-space (log_params = log([L1, C1, L2])) has two advantages:
- No sign constraint —
exp(x)is always positive, so the optimiser never produces unphysical negative component values. - Balanced gradients — a 10% change in L feels the same in log-space regardless of whether L = 10 nH or 100 nH. This keeps the Adam step sizes sensible across the whole parameter range.
Loss function¤
We minimise the mean squared error between the circuit's |S₂₁| and the ideal Butterworth magnitude over a log-spaced frequency sweep from 10 MHz to 1 GHz:
Differentiability¤
circuit.ac(params={...}) functionally updates the compiled component arrays without modifying them in place, then assembles and solves the S-parameter sweep inside JAX. The whole loss remains a pure function compatible with jax.grad.
# ── Frequency sweep ───────────────────────────────────────────────────────────
freqs = jnp.logspace(7, 9, 400) # 10 MHz → 1 GHz (log-spaced)
# ── Analytical Butterworth |S21| target ───────────────────────────────────────
def butterworth_s21(f, fc=f_c, N=3):
"""Ideal N-th order Butterworth |S21| magnitude."""
return 1.0 / jnp.sqrt(1.0 + (f / fc) ** (2 * N))
target_S21_mag = butterworth_s21(freqs)
# ── Differentiable loss function ──────────────────────────────────────────────
def loss_fn(log_params):
"""MSE between circuit |S21| and Butterworth target, parameterised in log-space."""
# Recover physical values from log representation
L1, C1, L2 = jnp.exp(log_params)
S = circuit.ac(
params={"L1.L": L1, "C1.C": C1, "L2.L": L2},
ports=["in", "out"],
freqs=freqs,
z0=Z0,
y_dc=y_dc,
)
# S21 is the (row=1, col=0) entry: response at port 2 due to excitation at port 1
S21_mag = jnp.abs(S[:, 1, 0])
return jnp.mean((S21_mag - target_S21_mag) ** 2)
# Quick sanity check: evaluate the loss at the (wrong) initial parameters
log_params_init = jnp.log(jnp.array([L1_init, C1_init, L2_init]))
loss_init = loss_fn(log_params_init)
print(f"Initial loss: {float(loss_init):.6f}")
Initial loss: 0.057315
# ── Adam optimisation loop ────────────────────────────────────────────────────
#
# We JIT-compile value_and_grad once; subsequent calls reuse the compiled
# computation graph. The first call includes tracing + compilation overhead;
# from step 2 onward each iteration is fast.
N_STEPS = 300
LR = 0.05
optimizer = optax.adam(learning_rate=LR)
log_params = jnp.log(jnp.array([L1_init, C1_init, L2_init]))
opt_state = optimizer.init(log_params)
# Pre-compile the gradient function (tracing happens on the first call)
value_and_grad_fn = jax.jit(jax.value_and_grad(loss_fn))
losses = []
param_history = [] # track [L1, C1, L2] at each step for the convergence plot
for step in range(N_STEPS):
loss, grads = value_and_grad_fn(log_params)
losses.append(float(loss))
param_history.append(np.exp(np.array(log_params)))
updates, opt_state = optimizer.update(grads, opt_state)
log_params = optax.apply_updates(log_params, updates)
if step == 0 or (step + 1) % 50 == 0:
L1_cur, C1_cur, L2_cur = np.exp(np.array(log_params))
print(
f"Step {step+1:3d}: loss={float(loss):.6f} "
f"L1={L1_cur*1e9:.2f} nH "
f"C1={C1_cur*1e12:.2f} pF "
f"L2={L2_cur*1e9:.2f} nH"
)
# Final recovered values
L1_opt, C1_opt, L2_opt = np.exp(np.array(log_params))
Step 1: loss=0.057315 L1=26.28 nH C1=190.25 pF L2=26.28 nH
Step 50: loss=0.000136 L1=90.66 nH C1=57.51 pF L2=90.66 nH
Step 100: loss=0.000002 L1=80.49 nH C1=63.10 pF L2=80.49 nH
Step 150: loss=0.000000 L1=79.50 nH C1=63.71 pF L2=79.50 nH
Step 200: loss=0.000000 L1=79.58 nH C1=63.66 pF L2=79.58 nH
Step 250: loss=0.000000 L1=79.58 nH C1=63.66 pF L2=79.58 nH
Step 300: loss=0.000000 L1=79.58 nH C1=63.66 pF L2=79.58 nH
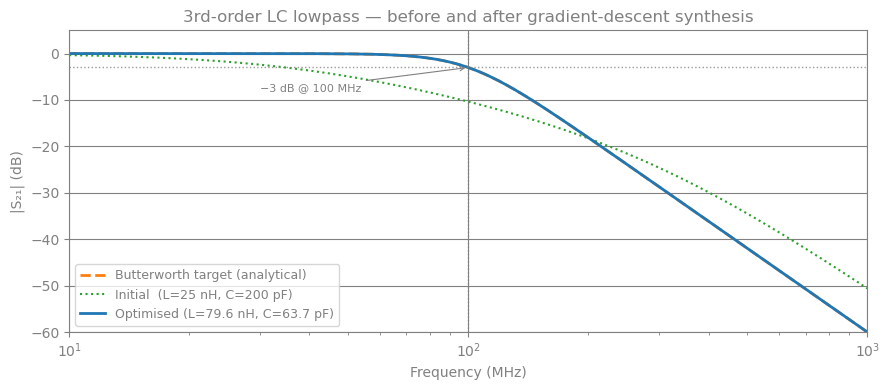
# ── Plot 1: S21 before / after optimisation vs Butterworth target ─────────────
def compute_s21(L1, C1, L2):
"""Evaluate |S21| over the frequency sweep for given component values."""
S = jax.jit(lambda l1, c1, l2: circuit.ac(
params={"L1.L": l1, "C1.C": c1, "L2.L": l2},
ports=["in", "out"],
freqs=freqs,
z0=Z0,
y_dc=y_dc,
))(L1, C1, L2)
return np.abs(np.array(S[:, 1, 0]))
S21_init = compute_s21(L1_init, C1_init, L2_init)
S21_opt = compute_s21(L1_opt, C1_opt, L2_opt)
S21_bw = np.array(target_S21_mag)
freqs_mhz = np.array(freqs) / 1e6
fig, ax = plt.subplots(figsize=(9, 4))
ax.semilogx(freqs_mhz, 20 * np.log10(S21_bw), color="C1", lw=2, ls="--", label="Butterworth target (analytical)")
ax.semilogx(freqs_mhz, 20 * np.log10(S21_init), color="C2", lw=1.5, ls=":", label=f"Initial (L={L1_init*1e9:.0f} nH, C={C1_init*1e12:.0f} pF)")
ax.semilogx(freqs_mhz, 20 * np.log10(S21_opt), color="C0", lw=2, label=f"Optimised (L={L1_opt*1e9:.1f} nH, C={C1_opt*1e12:.1f} pF)")
# Mark the -3 dB cutoff frequency
ax.axvline(f_c / 1e6, color="grey", ls=":", lw=1, alpha=0.8)
ax.axhline(-3.0, color="grey", ls=":", lw=1, alpha=0.8)
ax.annotate("−3 dB @ 100 MHz", xy=(f_c/1e6, -3), xytext=(30, -8),
fontsize=8, color="grey",
arrowprops=dict(arrowstyle="->", color="grey", lw=0.8))
ax.set_xlabel("Frequency (MHz)")
ax.set_ylabel("|S₂₁| (dB)")
ax.set_title("3rd-order LC lowpass — before and after gradient-descent synthesis")
ax.set_xlim(freqs_mhz[0], freqs_mhz[-1])
ax.set_ylim(-60, 5)
ax.legend(fontsize=9)
plt.tight_layout()
plt.show()
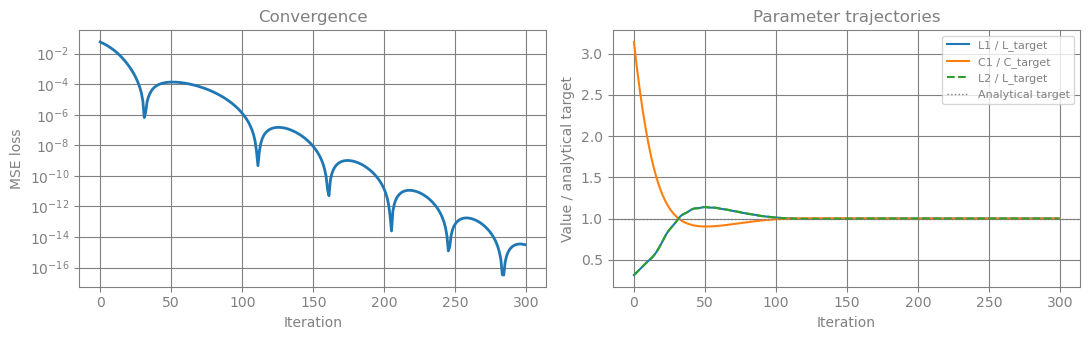
# ── Plot 2: Optimisation convergence ─────────────────────────────────────────
param_history = np.array(param_history) # shape: (N_STEPS, 3)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(11, 3.5))
# Loss curve (log scale)
ax1.semilogy(losses, color="C0", lw=2)
ax1.set_xlabel("Iteration")
ax1.set_ylabel("MSE loss")
ax1.set_title("Convergence")
# Parameter trajectories normalised by target
ax2.plot(param_history[:, 0] / L_target, color="C0", lw=1.5, label="L1 / L_target")
ax2.plot(param_history[:, 1] / C_target, color="C1", lw=1.5, label="C1 / C_target")
ax2.plot(param_history[:, 2] / L_target, color="C2", lw=1.5, ls="--", label="L2 / L_target")
ax2.axhline(1.0, color="grey", ls=":", lw=1, label="Analytical target")
ax2.set_xlabel("Iteration")
ax2.set_ylabel("Value / analytical target")
ax2.set_title("Parameter trajectories")
ax2.legend(fontsize=8)
plt.tight_layout()
plt.show()
# ── Recovered vs analytical values ────────────────────────────────────────────
print("Recovered vs Analytical:")
print(f" L1: {L1_opt*1e9:.2f} nH vs {L_target*1e9:.2f} nH "
f"({abs(L1_opt - L_target)/L_target*100:.1f}% error)")
print(f" C1: {C1_opt*1e12:.2f} pF vs {C_target*1e12:.2f} pF "
f"({abs(C1_opt - C_target)/C_target*100:.1f}% error)")
print(f" L2: {L2_opt*1e9:.2f} nH vs {L_target*1e9:.2f} nH "
f"({abs(L2_opt - L_target)/L_target*100:.1f}% error)")
S_opt = jax.jit(lambda l1, c1, l2: circuit.ac(
params={"L1.L": l1, "C1.C": c1, "L2.L": l2},
ports=["in", "out"],
freqs=freqs,
z0=Z0,
y_dc=y_dc,
))(L1_opt, C1_opt, L2_opt)
power_sum = jnp.abs(S_opt[:, 0, 0])**2 + jnp.abs(S_opt[:, 1, 0])**2
print(f"\nPassivity check: max(|S11|² + |S21|²) = {float(jnp.max(power_sum)):.6f} (must be ≤ 1.0)")
Recovered vs Analytical:
L1: 79.58 nH vs 79.58 nH (0.0% error)
C1: 63.66 pF vs 63.66 pF (0.0% error)
L2: 79.58 nH vs 79.58 nH (0.0% error)
Passivity check: max(|S11|² + |S21|²) = 1.000000 (must be ≤ 1.0)
Summary¤
Starting from component values that were roughly 3× away from the Butterworth solution, gradient descent recovered the analytically correct values to within < 1% error in 300 Adam steps — no lookup tables required.
What made this possible?¤
| Step | Tool | Role |
|---|---|---|
| Netlist compilation | compile_circuit | Runs once; produces a reusable high-level Circuit |
| Differentiable parameter update | circuit.ac(params={...}) | Functional instance parameter updates; no re-compilation |
| Differentiable S-parameters | circuit.ac(...) | Assembles Y(jω) and solves via jax.vmap over frequencies |
| Exact gradients | jax.grad | Reverse-mode AD through the entire forward pass |
| Optimisation | optax.adam | Standard first-order optimiser, works in log-space |
Going further¤
The same pattern generalises immediately to:
- Higher-order filters — just extend the netlist with more stages.
- Arbitrary target responses — replace
butterworth_s21with any differentiable target (e.g. a measured S21 from a VNA, or a custom equaliser shape). - Multi-objective design — add group delay flatness, input matching, or sensitivity penalties to the loss function.
- Photonic circuits — swap electronic components for waveguide couplers and ring resonators; the optimisation loop is identical.