Van der Pol Oscillator Tuning via Backpropagation through Harmonic Balance¤
Inverse design will be used to tune a nonlinear Van der Pol oscillator's frequency and limit-cycle amplitude to prescribed targets by backpropagating through the Harmonic Balance solver, resulting in the following:
The following is how this is performed in circulax.
The problem¤
Given a Van der Pol oscillator (a nonlinear LC tank with negative resistance), tune its parameters so the oscillation hits a precise target frequency and amplitude. This is a joint nonlinear design problem with no closed-form solution.
Traditional approach: Sweep μ over a grid of values, run a transient simulation to steady state for each, measure the amplitude, and read off the closest match. For a two-parameter sweep (frequency + amplitude) the cost is quadratic in grid resolution.
circulax approach: jax.grad through the HB Newton solver via Optimistix's implicit differentiation. The solver finds the periodic steady state in ~15 Newton steps; the gradient is computed by differentiating through that fixed-point computation. A single gradient call replaces the entire parameter sweep.
Circuit: Van der Pol oscillator¤
The Van der Pol element has a cubic I–V characteristic:
- For small \(|V|\): slope \(= -\mu G_0 < 0\) — negative resistance, oscillation grows
- Cubic term limits amplitude at \(|V| \approx \sqrt{3/G_0}\) — stable limit cycle
The element is placed in parallel with an LC tank:
top_node ─── VDP ─── GND (Van der Pol: negative resistance + cubic saturation)
top_node ─── L1 ─── GND (inductor)
top_node ─── C1 ─── GND (capacitor)
top_node ─── Rdamp ─── GND (small tank loss, models coil resistance)
The tank resonates at \(f_0 = 1/(2\pi\sqrt{LC})\). The VDP element pumps energy in at small amplitudes (negative conductance dominates) and absorbs energy at large amplitudes (cubic term dominates), creating a stable limit cycle.
import jax
import jax.numpy as jnp
import numpy as np
import optax
import plotly.graph_objects as go
import plotly.io as pio
from plotly.subplots import make_subplots
from circulax import compile_circuit
from circulax.components.base_component import PhysicsReturn, Signals, States, component
from circulax.components.electronic import Capacitor, Inductor, Resistor
# 64-bit precision is important: HB Newton requires accurate Jacobians, and
# gradient-based optimisation accumulates floating-point error across steps.
jax.config.update("jax_enable_x64", True)
pio.templates.default = "plotly_white"
pio.renderers.default = "png"
Defining the Van der Pol component¤
Custom components are plain Python functions decorated with @component. The decorator generates an Equinox module whose parameters (mu, G0) are JAX-traceable leaves, making the component compatible with jax.vmap, jax.jacfwd, and jax.grad.
@component(ports=("p1", "p2"))
def VanDerPolElement(signals: Signals, s: States, mu: float = 2.0, G0: float = 0.01) -> PhysicsReturn:
"""Nonlinear two-terminal element with cubic I-V characteristic.
I(V) = -mu*G0*V + (G0/3)*V^3
The first term is a negative conductance (-mu*G0 < 0), which supplies
energy to the tank when |V| is small. The cubic term (G0/3)*V^3 saturates
the gain at large amplitudes, producing a stable oscillation.
Limit-cycle amplitude (fundamental, from harmonic balance energy balance):
-mu*G0*A + G0/4*A^3 = 0 --> A = 2*sqrt(mu)
With G0=0.01 and mu=2.0: A = 2*sqrt(2) ≈ 2.83 V
Note: mu appears only in the linear term so that the limit-cycle amplitude
A = 2*sqrt(mu) is strongly tunable — a factor-of-4 change in mu moves A by
2×. If mu were also in the cubic term, amplitude would saturate at ~2 V
regardless of mu.
"""
v = signals.p1 - signals.p2
i = -mu * G0 * v + (G0 / 3.0) * v**3
return {"p1": i, "p2": -i}, {}
# Quick smoke-test: check that the I-V slope at V=0 is -mu*G0 (negative conductance)
vdp_test = VanDerPolElement(mu=2.0, G0=0.01)
f_test, _ = vdp_test(p1=0.1, p2=0.0)
print(f"VDP I at V=0.1 V : {f_test['p1']:.6f} A (expected {-2.0*0.01*0.1 + (0.01/3)*0.1**3:.6f} A)")
print(f"Expected limit-cycle amplitude: 2*sqrt(mu) = {2*np.sqrt(2.0):.3f} V (at mu=2, G0=0.01)")
VDP I at V=0.1 V : -0.001997 A (expected -0.001997 A)
Expected limit-cycle amplitude: 2*sqrt(mu) = 2.828 V (at mu=2, G0=0.01)
Building and compiling the circuit¤
All four elements connect between the same top_node and GND — they are in parallel. The LC tank sets the oscillation frequency; Rdamp models the finite Q of a real inductor (10 kΩ is intentionally large so tank losses are much smaller than the VDP negative resistance, ensuring oscillation).
The tuple syntax for connections ("GND,p1": ("VDP,p2", "C1,p2", ...)) joins multiple ports to the same node in a single line — equivalent to writing each pair separately.
# ── Circuit parameters ────────────────────────────────────────────────────────
L_val = 1e-6 # H (1 µH)
C_val = 1e-9 # F (1 nF)
R_damp = 1e4 # Ω (10 kΩ tank loss — small, Q ≈ R_damp * sqrt(C/L) ≈ 316)
f0 = 1.0 / (2.0 * np.pi * np.sqrt(L_val * C_val))
print(f"Tank resonant frequency : {f0 / 1e6:.4f} MHz")
print(f"Tank Q-factor (Rdamp) : {R_damp * np.sqrt(C_val / L_val):.1f}")
print(f"VDP negative conductance: {-2.0 * 0.01:.4f} S (at mu=2, G0=0.01)")
print(f"Tank loss conductance : {1.0 / R_damp:.6f} S (1/Rdamp)")
print(f"Net gain margin : {abs(-2.0 * 0.01) / (1.0 / R_damp):.0f}× >> 1, oscillation guaranteed")
# ── Netlist ──────────────────────────────────────────────────────────────────
# All four elements are in parallel between top_node and GND.
# GND is declared as the reserved ground instance and assigned node 0.
vdp_net = {
"instances": {
"VDP": {"component": "vdp", "settings": {"mu": 2.0, "G0": 0.01}},
"L1": {"component": "inductor", "settings": {"L": L_val}},
"C1": {"component": "capacitor", "settings": {"C": C_val}},
"Rdamp": {"component": "resistor", "settings": {"R": R_damp}},
"GND": {"component": "ground"},
},
"connections": {
# Connect all negative terminals to GND (node 0)
"GND,p1": ("VDP,p2", "L1,p2", "C1,p2", "Rdamp,p2"),
# Connect all positive terminals to the same top_node
"VDP,p1": ("L1,p1", "C1,p1", "Rdamp,p1"),
},
"ports": {"osc": "VDP,p1"},
}
models = {
"vdp": VanDerPolElement,
"inductor": Inductor,
"capacitor": Capacitor,
"resistor": Resistor,
"ground": lambda: 0,
}
# compile_circuit runs once; scalar params passed to circuit.hb(...) update
# instance values without re-compiling the topology.
circuit = compile_circuit(vdp_net, models)
num_vars = circuit.sys_size
print(f"\nSystem size : {num_vars} unknowns")
print(f"Named ports : {list(vdp_net['ports'])}")
# Advanced initialization detail: the custom HB warm starts below need the flat
# state-vector index of the oscillator port.
osc_idx = circuit.port_map["osc"]
print("Oscillator port: 'osc'")
# DC operating point: V=0 is the only fixed point (the VDP element has I(0)=0)
y_dc = circuit.dc()
print(f"DC operating point: max|y_dc| = {float(jnp.max(jnp.abs(y_dc))):.2e} V (trivially zero)")
Tank resonant frequency : 5.0329 MHz
Tank Q-factor (Rdamp) : 316.2
VDP negative conductance: -0.0200 S (at mu=2, G0=0.01)
Tank loss conductance : 0.000100 S (1/Rdamp)
Net gain margin : 200× >> 1, oscillation guaranteed
System size : 3 unknowns
Named ports : ['osc']
Oscillator port: 'osc'
DC operating point: max|y_dc| = 0.00e+00 V (trivially zero)
Part 1 — Harmonic Balance finds the limit cycle¤
Transient simulation would need to integrate forward in time until the oscillation envelope settles — often hundreds of RF cycles. Harmonic Balance finds the periodic steady state directly by solving for the Fourier coefficients of the waveform.
circuit.hb(...) builds and runs the HB solve from the compiled circuit. The result is JIT-compatible and differentiable end-to-end, while named ports such as "osc" keep waveform extraction readable.
N_harm = 7 # 7 harmonics → K = 15 time points per period
K = 2 * N_harm + 1
# Pass osc_node so circuit.hb automatically tries several sinusoidal initial
# amplitudes and selects the limit-cycle solution.
y_time, y_freq = circuit.hb(freq=f0, harmonics=N_harm, y0=y_dc, osc_node="osc")
print(f"y_time shape : {y_time.shape} (K={K} time samples × {num_vars} nodes)")
print(f"y_freq shape : {y_freq.shape} ({N_harm+1} harmonics × {num_vars} nodes)")
y_osc_freq = circuit.port(y_freq, "osc")
# y_freq[0] is the DC component, y_freq[1] is the fundamental, etc.
# Two-sided amplitude at harmonic k>=1 is 2 * |y_freq[k]| (rfft folds negative freqs)
A_dc = float(jnp.abs(y_osc_freq[0]))
A_fund = float(2.0 * jnp.abs(y_osc_freq[1]))
A_2nd = float(2.0 * jnp.abs(y_osc_freq[2]))
A_3rd = float(2.0 * jnp.abs(y_osc_freq[3]))
print("\nOscillator port 'osc' harmonic amplitudes:")
print(f" DC (0f0) : {A_dc:.4f} V")
print(f" Fundamental f0 : {A_fund:.4f} V")
print(f" 2nd harmonic : {A_2nd:.4f} V ({A_2nd/A_fund*100:.1f}% of fundamental)")
print(f" 3rd harmonic : {A_3rd:.4f} V ({A_3rd/A_fund*100:.1f}% of fundamental)")
print(f"\nExpected amplitude (VdP limit cycle): ~2*sqrt(mu) = {2*np.sqrt(2.0):.3f} V")
y_time shape : (15, 3) (K=15 time samples × 3 nodes)
y_freq shape : (8, 3) (8 harmonics × 3 nodes)
Oscillator port 'osc' harmonic amplitudes:
DC (0f0) : 0.0000 V
Fundamental f0 : 2.9139 V
2nd harmonic : 0.0000 V (0.0% of fundamental)
3rd harmonic : 0.2501 V (8.6% of fundamental)
Expected amplitude (VdP limit cycle): ~2*sqrt(mu) = 2.828 V
# ── Plot: time-domain waveform and harmonic spectrum ─────────────────────────
T = 1.0 / f0
t_ns = np.linspace(0.0, T * 1e9, K, endpoint=False)
v_osc = np.array(circuit.port(y_time, "osc"))
harmonics = np.arange(N_harm + 1)
scale = np.where(harmonics == 0, 1.0, 2.0)
spectrum = scale * np.abs(np.array(circuit.port(y_freq, "osc")))
tick_labels = ["DC" if k == 0 else f"{k}f₀" for k in harmonics]
fig = make_subplots(
rows=1, cols=2,
subplot_titles=(
f"Van der Pol limit cycle — f₀ = {f0/1e6:.3f} MHz",
"Harmonic spectrum",
),
)
fig.add_trace(
go.Scatter(x=t_ns, y=v_osc, mode="lines+markers",
marker=dict(size=7), line=dict(width=1.5),
name=f"V_osc (HB, K={K})"),
row=1, col=1,
)
fig.add_hline(y=0, line_dash="dash", line_color="grey", line_width=0.7, row=1, col=1)
fig.add_trace(
go.Bar(x=tick_labels, y=spectrum, marker_color="#636EFA", opacity=0.85, name="spectrum"),
row=1, col=2,
)
fig.update_xaxes(title_text="Time (ns)", row=1, col=1)
fig.update_yaxes(title_text="Voltage (V)", row=1, col=1)
fig.update_xaxes(title_text="Harmonic", row=1, col=2)
fig.update_yaxes(title_text="Amplitude (V)", row=1, col=2)
fig.update_layout(margin=dict(t=80, b=60, l=60, r=60), height=450, showlegend=True)
fig.show()
print("The odd-harmonic dominance (f0, 3f0, 5f0) is a hallmark of the symmetric cubic nonlinearity.")
print("Even harmonics (2f0, 4f0) are near-zero because I(-V) = -I(V) — the VDP element is odd.")
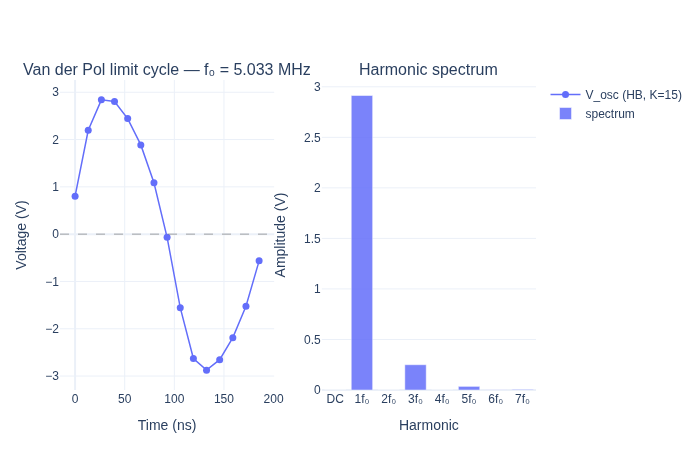
The odd-harmonic dominance (f0, 3f0, 5f0) is a hallmark of the symmetric cubic nonlinearity.
Even harmonics (2f0, 4f0) are near-zero because I(-V) = -I(V) — the VDP element is odd.
Part 2 — Gradient-based amplitude tuning¤
Goal: find the value of μ such that the fundamental amplitude equals a target \(A_{\text{target}}\).
The key insight: circuit.hb(params={...}) is end-to-end differentiable with respect to scalar JAX values passed as instance parameters. The whole loss computation is a valid JAX program that jax.grad can differentiate through.
Optimistix's FixedPointIteration implements implicit differentiation: the gradient of the fixed-point solution with respect to μ is computed via the implicit function theorem rather than unrolling the Newton iterations.
A_target = 1.5 # V (requires mu* = (A_target/2)^2 = 0.5625)
# Fixed warm start for the loss function: sinusoidal at 3.5 V at osc_idx, all
# other variables zero. This advanced initialization detail uses the flat state
# vector because HB solves for all time samples at once.
_phase = 2.0 * jnp.pi * jnp.arange(K, dtype=jnp.float64) / K
y_flat_warmstart = (
jnp.zeros(K * num_vars, dtype=jnp.float64)
.at[jnp.arange(K) * num_vars + osc_idx].set(3.5 * jnp.sin(_phase))
)
def loss_fn_mu(mu: jax.Array) -> jax.Array:
"""Squared error between fundamental amplitude and target, as a function of mu."""
_, y_freq_new = circuit.hb(
freq=f0,
harmonics=N_harm,
y0=y_dc,
params={"VDP.mu": mu},
y_flat_init=y_flat_warmstart,
)
A_fund = 2.0 * jnp.abs(circuit.port(y_freq_new, "osc")[1])
return (A_fund - A_target) ** 2
# Test: evaluate loss and gradient at the default mu=2.0
mu_test = jnp.array(2.0)
loss_val, grad_val = jax.value_and_grad(loss_fn_mu)(mu_test)
print(f"At mu=2.0: loss = {float(loss_val):.4f} V², grad = {float(grad_val):.4f} V²/[mu]")
print(f" Current amplitude ≈ {float(jnp.sqrt(loss_val)) + A_target:.3f} V, target = {A_target} V")
print(" Positive gradient → decreasing mu reduces amplitude toward target")
# ── Gradient descent — scalar parameter, no need for Adam ───────────────────
mu = jnp.array(3.0) # start above the solution (A=2*sqrt(3)≈3.46 V)
lr = 0.05
mu_history = [float(mu)]
loss_history = []
val_and_grad_jit = jax.jit(jax.value_and_grad(loss_fn_mu))
print(f"\nGradient descent (lr={lr}, starting from mu={float(mu):.1f}):")
for step in range(80):
loss, g = val_and_grad_jit(mu)
loss_history.append(float(loss))
mu = mu - lr * g
mu_history.append(float(mu))
if step % 20 == 0 or step == 79:
_, yf_cur = circuit.hb(freq=f0, harmonics=N_harm, y0=y_dc, params={"VDP.mu": mu}, osc_node="osc")
A_cur = float(2.0 * jnp.abs(circuit.port(yf_cur, "osc")[1]))
print(f" Step {step:3d}: mu = {float(mu):.4f}, loss = {float(loss):.6f}, A_fund = {A_cur:.4f} V")
mu_opt = float(mu)
print(f"\nOptimised mu = {mu_opt:.4f} (analytical: {(A_target/2)**2:.4f})")
At mu=2.0: loss = 1.9992 V², grad = 3.4345 V²/[mu]
Current amplitude ≈ 2.914 V, target = 1.5 V
Positive gradient → decreasing mu reduces amplitude toward target
Gradient descent (lr=0.05, starting from mu=3.0):
Step 0: mu = 2.5087, loss = 4.018053, A_fund = 3.2403 V
Step 20: mu = 0.5763, loss = 0.013698, A_fund = 1.5301 V
Step 40: mu = 0.5077, loss = 0.000000, A_fund = 1.5002 V
Step 60: mu = 0.5075, loss = 0.000000, A_fund = 1.4999 V
Step 79: mu = 0.5075, loss = 0.000000, A_fund = 1.4999 V
Optimised mu = 0.5075 (analytical: 0.5625)
# ── Compute waveforms before and after optimisation ───────────────────────────
_, yf_before = circuit.hb(freq=f0, harmonics=N_harm, y0=y_dc, params={"VDP.mu": jnp.array(2.0)}, osc_node="osc")
yt_after, yf_after = circuit.hb(freq=f0, harmonics=N_harm, y0=y_dc, params={"VDP.mu": jnp.array(mu_opt)}, osc_node="osc")
A_before = float(2.0 * jnp.abs(circuit.port(yf_before, "osc")[1]))
A_after = float(2.0 * jnp.abs(circuit.port(yf_after, "osc")[1]))
v_before = np.array(circuit.port(y_time, "osc"))
v_after = np.array(circuit.port(yt_after, "osc"))
fig = make_subplots(
rows=1, cols=2,
subplot_titles=(
"Before and after μ tuning",
f"Amplitude tuning convergence (target {A_target} V)",
),
)
fig.add_trace(
go.Scatter(x=t_ns, y=v_before, mode="lines", line=dict(width=2),
name=f"μ=2.00 → A={A_before:.2f} V (initial)"),
row=1, col=1,
)
fig.add_trace(
go.Scatter(x=t_ns, y=v_after, mode="lines", line=dict(width=2.5, dash="dash"),
name=f"μ={mu_opt:.2f} → A={A_after:.2f} V (optimised)"),
row=1, col=1,
)
fig.add_hline(y= A_target, line_dash="dot", line_color="grey", line_width=0.8, row=1, col=1)
fig.add_hline(y=-A_target, line_dash="dot", line_color="grey", line_width=0.8, row=1, col=1)
fig.add_trace(
go.Scatter(x=list(range(len(loss_history))), y=loss_history, mode="lines",
line=dict(width=2), name="loss", showlegend=False),
row=1, col=2,
)
fig.update_xaxes(title_text="Time (ns)", row=1, col=1)
fig.update_yaxes(title_text="Voltage (V)", row=1, col=1)
fig.update_xaxes(title_text="Gradient descent step", row=1, col=2)
fig.update_yaxes(title_text="Loss (V²)", type="log", row=1, col=2)
fig.update_layout(margin=dict(t=80, b=100, l=60, r=60), height=520, legend=dict(orientation="h", y=-0.25, x=0.5, xanchor="center"))
fig.show()
print(f"Amplitude error after optimisation: {abs(A_after - A_target)*1000:.2f} mV")
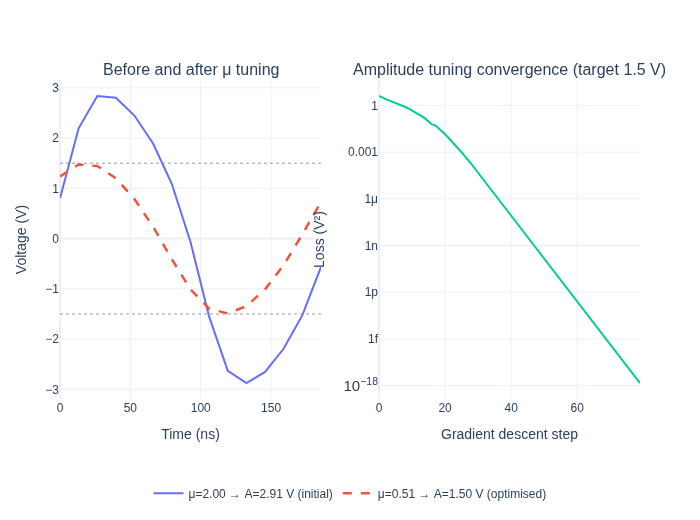
Amplitude error after optimisation: 0.11 mV
Part 3 — Joint tuning: frequency and amplitude¤
Now we solve the harder problem: simultaneously tune L, C, and μ so the oscillator hits a new target frequency (8 MHz, shifted from 5 MHz) and a target amplitude (1.0 V).
This is a joint nonlinear design problem. The traditional approach would be a 3D sweep over (L, C, μ) — thousands of HB solves just to map the landscape. With jax.grad we get the exact gradient with one HB solve, and Adam navigates directly to the solution.
Log-space parameterisation keeps all three parameters positive and balances their gradients: a 10% change in L feels the same as a 10% change in μ, regardless of the absolute scale. We also pass the resonant frequency (derived from L and C) directly to circuit.hb(...) — this ensures the HB discretisation always matches the actual oscillation frequency, which is essential for convergence when L and C are changing.
f_target = 8e6 # Hz — 8 MHz target (up from ~5 MHz)
A_target_j = 1.0 # V — 1 V fundamental amplitude
LC_target = 1.0 / (2.0 * np.pi * f_target) ** 2
print(f"Target frequency : {f_target/1e6:.1f} MHz")
print(f"Required L*C product: {LC_target:.3e} H·F")
print(f"Starting L={L_val*1e6:.2f} µH, C={C_val*1e9:.2f} nF → f0={f0/1e6:.3f} MHz")
# Fixed sinusoidal warm start for the joint optimisation loss — amplitude 2 V at osc_idx,
# all other nodes zero. This is advanced initialization over the flat HB state vector.
_phase_k = 2.0 * jnp.pi * jnp.arange(K, dtype=jnp.float64) / K
y_flat_hb_init = (
jnp.zeros(K * num_vars, dtype=jnp.float64)
.at[jnp.arange(K) * num_vars + osc_idx].set(3.5 * jnp.sin(_phase_k))
)
def loss_joint(log_params: jax.Array) -> jax.Array:
"""Joint loss over (log_L, log_C, log_mu) for frequency + amplitude targets."""
log_L, log_C, log_mu = log_params
L = jnp.exp(log_L)
C = jnp.exp(log_C)
mu = jnp.exp(log_mu)
f_resonant = 1.0 / (2.0 * jnp.pi * jnp.sqrt(L * C))
_, y_freq_j = circuit.hb(
freq=f_resonant,
harmonics=N_harm,
y0=jnp.zeros(num_vars),
params={"L1.L": L, "C1.C": C, "VDP.mu": mu},
y_flat_init=y_flat_hb_init,
)
A_fund = 2.0 * jnp.abs(circuit.port(y_freq_j, "osc")[1])
loss_freq = ((f_resonant - f_target) / f_target) ** 2
loss_amp = ((A_fund - A_target_j) / A_target_j) ** 2
return loss_freq + loss_amp
# Sanity check
log_params_0 = jnp.log(jnp.array([L_val, C_val, 2.0]))
loss_0 = loss_joint(log_params_0)
print(f"\nInitial joint loss: {float(loss_0):.4f} (freq error + amplitude error)")
# ── Adam optimisation ─────────────────────────────────────────────────────────
optimizer = optax.adam(0.05)
log_params = log_params_0
opt_state = optimizer.init(log_params)
losses_joint = []
param_log_hist = [np.array(log_params)]
val_grad_joint = jax.jit(jax.value_and_grad(loss_joint))
print("\nAdam optimisation (200 steps, lr=0.05):")
for i in range(200):
loss, grads = val_grad_joint(log_params)
losses_joint.append(float(loss))
updates, opt_state = optimizer.update(grads, opt_state)
log_params = optax.apply_updates(log_params, updates)
param_log_hist.append(np.array(log_params))
if i % 50 == 0 or i == 199:
L_c, C_c, mu_c = np.exp(np.array(log_params))
f_c_cur = 1.0 / (2.0 * np.pi * np.sqrt(L_c * C_c))
print(f" Step {i:3d}: loss={float(loss):.5f}, f={f_c_cur/1e6:.3f} MHz, L={L_c*1e6:.3f} µH, C={C_c*1e9:.3f} nF, mu={mu_c:.3f}")
L_opt, C_opt, mu_opt_j = np.exp(np.array(log_params))
f_opt = 1.0 / (2.0 * np.pi * np.sqrt(L_opt * C_opt))
print(f"\nFinal: f={f_opt/1e6:.4f} MHz (target {f_target/1e6:.1f} MHz), L={L_opt*1e6:.4f} µH, C={C_opt*1e9:.4f} nF, mu={mu_opt_j:.4f}")
Target frequency : 8.0 MHz
Required L*C product: 3.958e-16 H·F
Starting L=1.00 µH, C=1.00 nF → f0=5.033 MHz
Initial joint loss: 3.8006 (freq error + amplitude error)
Adam optimisation (200 steps, lr=0.05):
Step 0: loss=3.80062, f=5.033 MHz, L=0.951 µH, C=1.051 nF, mu=1.902
Step 50: loss=0.08338, f=8.245 MHz, L=0.235 µH, C=1.588 nF, mu=0.413
Step 100: loss=0.01063, f=8.013 MHz, L=0.223 µH, C=1.770 nF, mu=0.305
Step 150: loss=0.00086, f=8.001 MHz, L=0.220 µH, C=1.797 nF, mu=0.271
Step 199: loss=0.00008, f=8.000 MHz, L=0.220 µH, C=1.802 nF, mu=0.261
Final: f=7.9998 MHz (target 8.0 MHz), L=0.2196 µH, C=1.8022 nF, mu=0.2614
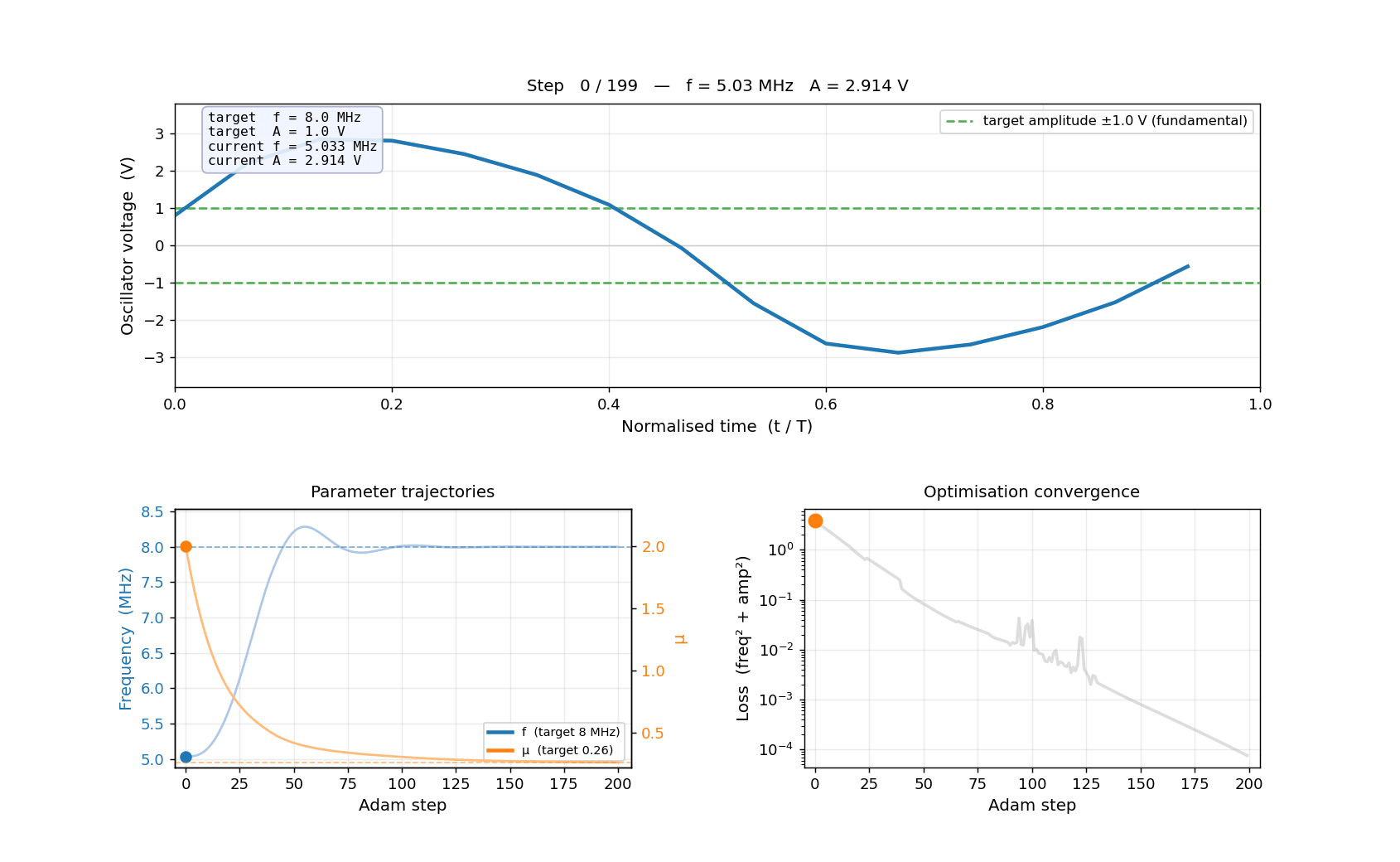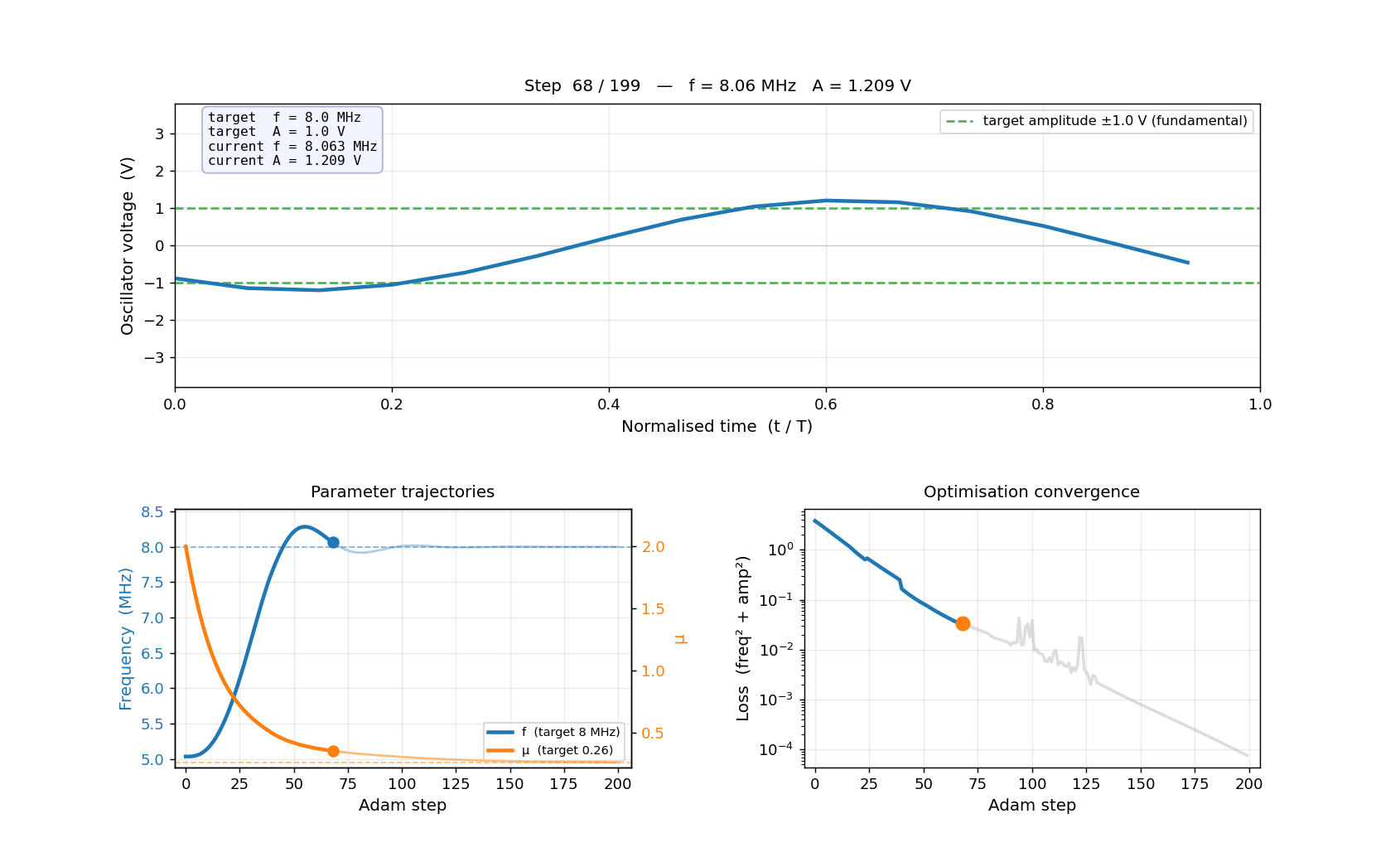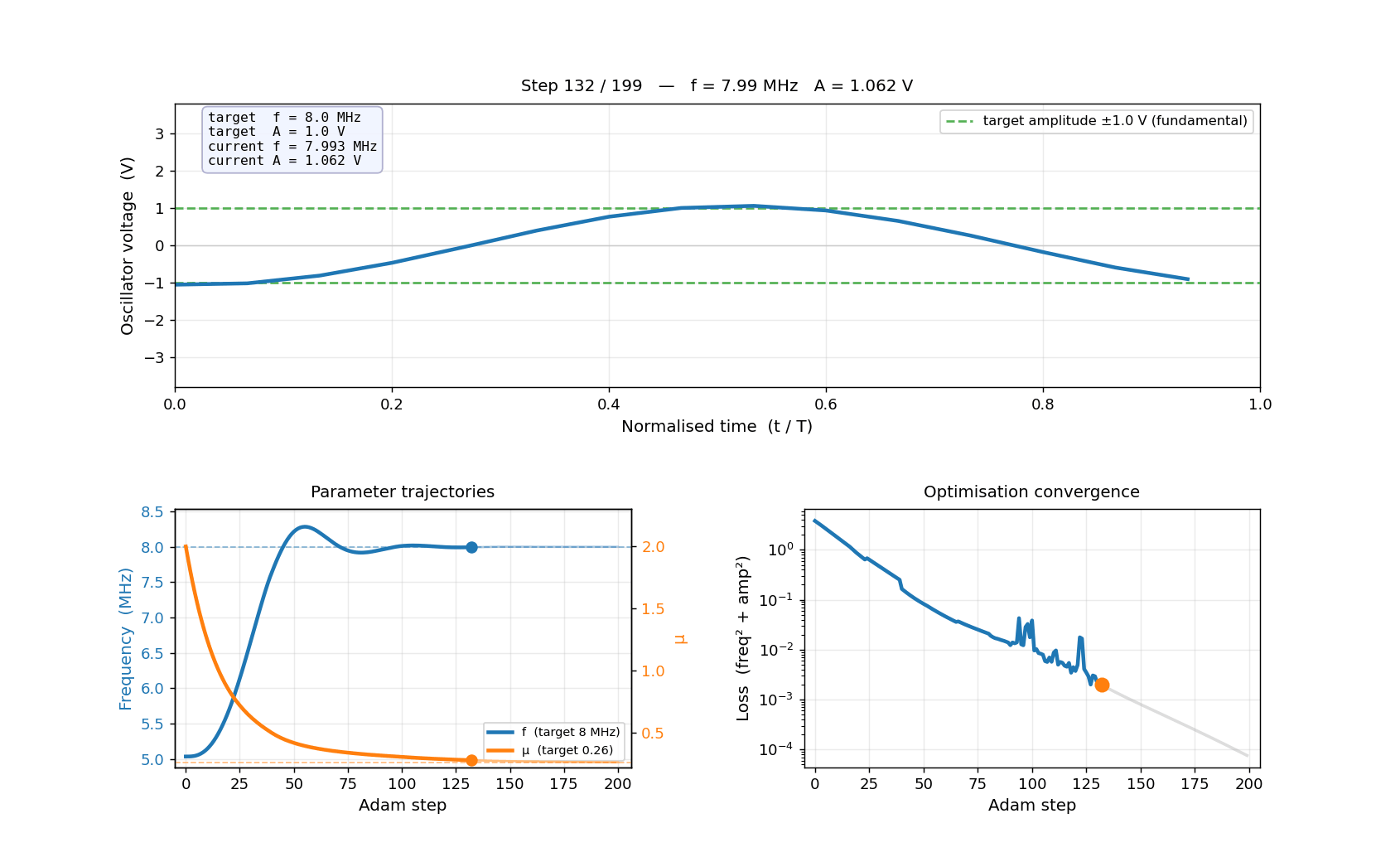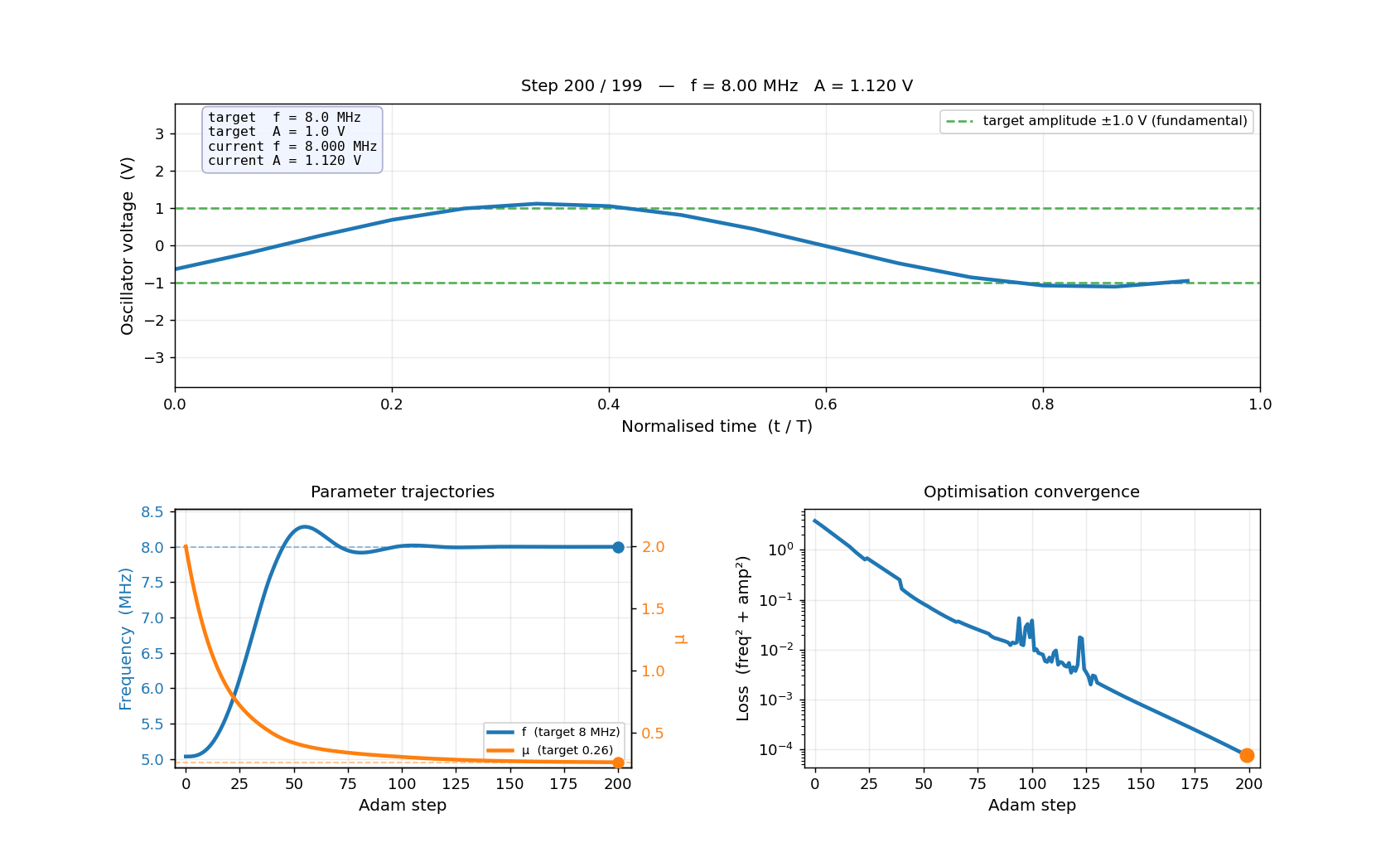
Pre-computing 51 HB solutions (stride=4)...
[ 1/51] step 0 — f=5.03 MHz, A=2.914 V, mu=2.000
[ 11/51] step 40 — f=7.66 MHz, A=1.483 V, mu=0.496
[ 21/51] step 80 — f=7.92 MHz, A=1.221 V, mu=0.331
[ 31/51] step 120 — f=8.00 MHz, A=1.149 V, mu=0.287
[ 41/51] step 160 — f=8.00 MHz, A=1.132 V, mu=0.268
[ 51/51] step 200 — f=8.00 MHz, A=1.120 V, mu=0.261
Done.
Saved → examples/inverse_design/oscillator_optimisation.gif
Frames: 51 Duration: 4.2s at 12 fps
Tip: drag-and-drop directly into PowerPoint (Insert → Pictures).
Summary¤
Starting from a Van der Pol oscillator running at ~5 MHz with ~2.8 V amplitude, gradient descent simultaneously tuned L, C, and μ to hit 8 MHz and 1.0 V in 200 Adam steps — with no grid sweeps and no manual iteration.
What made this possible?¤
| Step | Tool | Role |
|---|---|---|
| Component definition | @component decorator | Generates JAX-traceable Equinox module |
| Netlist compilation | compile_circuit | Runs once; produces a reusable high-level Circuit |
| Differentiable parameter update | circuit.hb(params={...}) | Functional instance parameter updates; no recompilation |
| Periodic steady state | circuit.hb(...) | Finds limit cycle in ~15 Newton steps; JIT-compatible |
| Exact gradients | jax.grad | Differentiates through the HB Newton solver via implicit differentiation |
| Optimisation | optax.adam | First-order optimiser in log-space; 200 steps to convergence |
Going further¤
The same pattern extends directly to:
- Phase noise minimisation — add a noise source and minimise the HB-estimated phase noise spectral density as a function of tank Q and bias point.
- Injection locking — add a small-signal source and tune the free-running frequency to lock at the injection frequency with maximum locking range.
- Coupled oscillator arrays — vmap the HB solve over an array of weakly coupled oscillators and optimise the coupling network for synchronisation.
- CMOS VCO design — replace the VDP element with a transistor-level cross-coupled pair (using NMOS / PMOS components from
circulax.components.electronic) and sweep the varactor capacitance as a differentiable parameter.